Muse® vs. Vivisimo Velocity Platform
In this post we make a comparison between the features in Muse™ 2.6.0.0 and Vivisimo Velocity Platform 7.5-6, related to building and running Connectors/Sources. This comparison is exclusively related to Federated Search capabilities and the environment for building, maintaining, configuring and running Connectors/Sources. Although this comparison is made by the developers of Muse™, we tried to be as objective and fair as possible. If you have any comments or suggestions, do not hesitate to contact us.
The comparison was drafted when we successfully finalized the integration of Muse™ Smart Connectors into Vivisimo Velocity Platform 7.5-6. The searches against Muse™ Smart Connectors was made available by writing a configurable Vivisimo Source Template connecting to our Muse™ Web Bridge API. The Vivisimo Source Template was quite complex as we needed more statefull operations, but we wrote it once and now Muse™’s Smart Connectors, making sometimes tens of requests, can be straight forward integrated into a Vivisimo search. You will see below in the comparison table that writing Velocity connectors which include authentication/authorization, subscribed database navigation, fine grained content extraction, Full Text availability, is a very difficult and sometimes impossible task but this is where integration with Muse™ Smart Connectors comes to help.
If you are interested in benefiting of 6000+ Smart Connectors, with quality and authoritative premium content, in your Vivisimo Platform (IBM InfoSphere Data Explorer) please contact us.
| Perspective | Item | Muse | Vivisimo Velocity Platform | |
|---|---|---|---|---|
| The Model | Who writes the connector? | The Muse team is creating the Source Package from A to Z following strict rules and Quality Assurance. Partners can as well create Muse Connectors with programmers. | Partner creates sources from A to Z, except few templates and is responsible with maintaining them. | |
| Philosophy | Muse’s philosophy was mainly for a central team developing the sources following rigorous and well documented procedures and naming conventions. The sources are uploaded into Global Source Factory after passing the Quality Assurance phase; the partner doesn’t have to have programmers to do further work or development of connectors, and the process is very well standardized. Muse can also offer externalization of source building together with the set of procedures and tools. | Velocity philosophy is mostly that the partner deals with source creation (apart for some few set of templates sources) and hence needs to have programmers handling this. | ||
| Team | Muse has a team that is doing Smart Connectors for 14 years now. We have well established procedures running thousands of connectors out of the box. | Velocity is more recent in business, and more recent focusing on meta-searching. One or two programmers can never compensate with the team of the product itself following all the internal procedures and Q&A and using tens of tools. Federated search capabilites were only included in Velocity in version 3. They were not there from the beginning, this means that some of the things were added in as adjustments. Muse was build for federated operations (search) in mind from the beginning. |
||
| The Workflow/ life-cycle of connectors | Workflow | There is a well defined Smart Connectors workflow from request to delivery time. There is meta information related to a Smart Connector so that it is safely identified: version, date created, build date, data service, type, protocol, status (released, defunct, defunct with replacement), etc. There are rigorous naming conventions. | Unaware of any. Didn’t see any meta information to identify such meta information elements. | |
| Logistics | There is a whole network for the source management both for the developer and for the partners installing Muse. There are internal indexes with the development sources, there are external indexes with the installed sources, and many other elements. | Although Velocity supports a master repository, synchronization is not done on a per source base, but rather on all of the resources (nodes). Sources are just a particular case. Without versions and other metadata fields it is hard to distinguish and be rigurous. Also merging at the level of code requires programmer expertise but not for an administrator. | ||
| Management | Easily managing thousands of sources | Managing ten or twenty sources could be OK, but managing hundreds of sources is impossible in Velocity. | ||
| Packaging | Muse is using compiled and packaged connectors with well defined pieces. There are tens of manual pages about the content of Muse Source packages. | Velocity is using interpreted connectors out of a single XML file for all the pieces a source involves. | ||
| Source Configuration and Capabilities | Configuration | In Muse configuration is detached from the source creation. It is a well defined and documented stage. | In Velocity configuration blends with the source code itself, no clear distinction, besides this will be done on each partner in place. In many places Vivisimo is incorectly using the term "configuration" for creating (developing) the connector (source). |
|
| Backup/Restore | Backup/Restore sources when updating, previous version can be restored. | No version, no backup. | ||
| Parameter uniformization | We strive for unifromization of thousands of sources to be able to edit them nicely in various Muse Administration Consoles. | There is no uniformization of the source parameters, just few parameters are output for existent sources on Velocity 7.5-6. | ||
| Exampe: SSL Certificate | In Muse each entity is correctly organized in its directory, in this case ${APPLICATION_HOME}/certificates (Muse is also very permissive in having resources anywhere on disk but for simple administration conventions are involved). For example support for handling HTTPS SSL Certificates sources in Muse it is a simple administrative task. There are visual selectors to upload the certificate file and you know precisely what to do where – this is not even a programmer’s job. | In Velocity you have to have access to the file system to upload a SSL certificate and you may have to modify the code of the source in order to change the reference to the HTTP certain certificate (in case it is the first time or you try to keep up some naming conventions). "ssl-cert NMToken Full path to a file containing an SSL certificate to be used for HTTPS connections." There is no documentation on any recommendation of how to handle the files and if naming conventions or certain directories should be followed. |
||
| Authenticators | For sources with authentication one can select from the authenticator library the suitable authenticator. For example sources using Web Access Management such as EZProxy can be configured in Muse. Authenticators are pluggable to more connectors and depending on their capabilities and can be interchanged. For example EZProxy authenticators can be configured for more connectors without the need to have the connector re-written. There is metainformation in the Muse logistics tools that accounts for these relations. In Muse there is a lot of semantic and parsing of the response in the authenticator library. | You have to write an authenticator directly in the source code. No pluggable authenticators – just a simple login function which transform two parameters into CGI parameters. So, just a syntactic help for the input side of the HTTP protocol but no semantics. Also there may be more HTTP requests needed for authentication not just a simple one. There’s also the case when it is necessary that the first request is not done by the authenticator. |
||
| Proxy PAC/Proxy redundancy | Complex proxy selection logic via interpreting standard Proxy Automatic Configuration Java script files (Proxy PAC). A particular case of this configuration is proxy redundancy for various data centers. The requests made by the connector to the source will pass through the proxy selected. | No Proxy PAC or other automatic interpretation. Only a single proxy can be specified per project (application) or per each parse action (inside the source). |
||
| URL Rewriting and MNM | Rewriting URLs for session migration from the server to end-user – otherwise the record URL will not be accessible from the browser session. When the end-user will click the URL will go to the Muse Navigation Manager (MNM) without the need for the end user to have any proxy in his/her browser. Complex rewritten of the page will happen and the MNM will act on behalf of the end-user. | Velocity does not have rewriting capabilities for the record URL, neither has a reverse proxy or other navigation manager available. | ||
| Importance of URL rewriting and MNM | In Muse Global Source Factory out of 6135 Sources 3368 requires MNM rewriting for having a functional Full Text (record) URL. That is over 54% of the Smart Connectors. | In Velocity this can only be offered through Muse connectivity. | ||
| Difficulty | Proxing and URL Rewriting is done transparently and nothing has to be coded in the connector. It is just a matter of configuring the Source Package or the application to specify running or not through a proxy and the MNM rewriting pattern [pattern which is generally pre-configured]. | No Proxy PAC, and for Proxy if it is set at source level (and not at the project level applying to all the sources) the source code must be modified. | ||
| Source Organization | In Muse you can have the same source called from different application and configured with different details. | If you need the same source in two different applications (projects) with slight configuration difference (e.g. a different authentication type) you will have to rename the source differently because the sources are held globally in the Velocity instance. Although Velocity allows for end-user login details to be passed transparently to sources a source can have more differences depending on the application (such as, for example, the Home URL). Also in practice organizational access is wanted. |
||
| Building (creating) connectors | General | No sense for comparison | It is even about writing the code directly, where the Velocity system is limited and the functions available are just for the very simple tasks, while in Muse there are plenty of APIs to use for various connector functions. Besides the things totally unsupported in Velocity system (such as URL Rewriting, Proxy PAC) there are other tasks that cannot be accomplished, such as mapping very distinct query grammars or the ones exposed in the next cells in the Query part. For binary protocols in Velocity there seems to be no direct support for plugging in libraries so workarounds such as creating an HTML/XML bridge are followed – for example the Z39.50 sources are queried through another distinct layer API (a HTTP CGI, not pertaining to Velocity), instead of querying directly. Hence for those connectors you externalize the whole logic and do it as you can if not offered by Vivisimo company. Even for HTTP based protocols or simple extensions the capabilities of the Velocity system seems limited. We have seen cases where for the Yahoo! BOSS API the partner used another server side PHP totally outside of the Velocity system because Velocity wasn’t able to handle the authentication part. This is not solid and is not configurable, neither standard – it’s just a workaround solution but it cannot fill the big gap in the capabilities of Velocity 7.5-6. This could have been easily integrated in a Smart Connector in Muse because the package handling that connectivity exist in Java and our Smart Connectors have adjacent mechanisms for managing all the necessary libraries at runtime. Velocity has other disadvantages for facing federated searching – URL rewriting and Navigation Manager for full text navigation is one of the most critical thing. Of course a Muse Proxy Software Integration Edition could help on this. Under this light it may not even make sense to go on with the comparison to see how things are done differently related to building connectors, because in Velocity some very important and critical things cannot be done at all. The practice also showed that even simple cases could end up wrongly coded in Velocity. Still, to sustain the above statements, the comparison continues below with exact evidences. |
|
| Connectors APIs and Connector Code Capabilities | In Muse even if not everything is covered by tools/wizards that generates the code, there are library APIs (in modulesutil.jar) which cater for the necessary functions. The modulesutil.jar is simply updated (hot deployment) if necessary on any installation. Everytime we consider we have more similar instances of pattern we create a new API or extend an existent one. And only for the unlikely event of being unsuitable you would have to write directly in Java. But at least it is Java and not a custom language you have to learn. | Even writing the code directly in Velocity cannot resolve certain situations such as parsing backward, Proxy PAC, complex queries, and many others as exposed in this report. | ||
| External protocol API libraries | Sources based on external development kit API (either text or binary) can easily be integrated in Muse and even delivered to an existent old installation without modification in the core related parts. We have logistics for packing all these libraries together with the source package and ensuring every plugin connection in Muse.This is done even automatically and supports hot deployment at run-time (no server restart). Few examples for when the necessary libraries (jar files) are delivered together with the connector: JSON.jar, tn5250j.ja, Database drivers, etc. | Different source protocols that needs external sepparate API (developmen kit) libraries cannot fit in the system. This has to be implemented as standaolne external Web application which expose a HTTP text (HTML/XML)API – a bridge in other words. This is a non standard, non uniform, time consuming creation, and mean losing initial protocol binds when creating the records/fields. Not to mention it has a very custom setup to be working and the partner would have to be careful with maintaing that piece of code as well. Examples are for Z39.50 or the workaround provided for Yahoo! BOSS API by using another server side PHP bit – this could have been easily integrated in a Smart Connector in Muse. |
||
| Component Sepparation | Muse has clear definitions about a Source Package (Smart Connector). In Muse entities (Configuration Profile, Query Translator, Authenticators, ExParser to name just a few) are correctly separated. These entities can then be used for other Source Packages as well. Also different programmers can work distributed on these components. | In Velocity everything is inside a single XML file which is the code of the connector. And writing such a connector from the scratch is sometimes considered as a "configuration" job but it really is coding. | ||
| Steps | Because HTML connectors are still the majority mainly we include most steps such a connector may need to do. The main steps a connector may need to be coded for are the following ones: – Authentication (sometimes navigation to the authentication page) * – Use session if necessary to save/load persistent native items* – Navigation to Database (can be several pages) – Selection of Database – Navigation to the Advanced Search Page – Query translation * – Query capabilities and remapping* – Perform the search * – Fetching and Parse results page (more requests if necessary) * – High performance extraction (citation parsing, date formatting) * – Extended Parsing – one request for each record * – Record Normalization * – URL Rewriting * – Error handling* The starred (*) ones are applicable for the API connectors as well. | Velocity only declares in documentation the following items as part of source creation and execution steps. The rest are mainly adjustments for fitting in: – Translating the query – Fetching Result Pages – Parsing/Normalizing the Result Pages |
||
| Problem decomposition | Muse offers API and tools for the fine grained steps. Muse tools go helping into very deep details such as citation parsing extraction and date formatting, mapping from Muse normalized query to dozens source grammar types and thousands of variations. | Velocity uses a coarse grain division, and let the details for the programmer to take care in any form (s)he wants. The tools ar for the coarse grain level. | ||
| Tools | In Muse the Muse Builder IDE (Integrated Development Environment) groups the tools necessary for development side. This also includes logistics tools to guide the workflow between the programmers tasks and Team Leader tasks and improves very much the work efficiency. There are also tools for the Quality Assurance. Below are the most important tools to be used for development: Source Package Assistant Connectors Generator Search Query Translator Generator Source Package Testing Each of them has sub-tools to be involved. There is a clear separation for the Muse Admin Consoles where only configuration is done as well as for other tools for source infrastructure. | The Velocity admin tool (same tool where creation and adminstration takes place) is mainly a set of variable configurations and addition of blocks, but for the most cases there is no visual configuration or editing of that block (for example the secondary parser for complex query transformation, additional parsing logic – any case that is more than clearly delimiting a field). All these in the context when even writing Velocity code directly is not solving the problem. |
||
| Query | Tree vs String | In Muse the normalized canonical query (ISR) is an XML tree on which the source translator is applied. Because we work directly on the tree we can convert to all the grammars type and not just to the one to one correspondences. | In Velocity the normalized canonical query although represented as a tree XML at some point is lost and the source form can only act on strings to do the transformations. There is only a one to one (no change in the structure of the grammar) possibility of mapping: "The default form template for search engine sources lets you specify one-to-one matches between field names and content names." [http://.../vivisimo/cgi-E18bin/admin?id=configuration-syntax-fields] |
|
| Different Grammar types | Every grammar can be handled in Muse and even visually through SQTG. We can convert into totally distinct grammars such as non parenthesized, postfix, infix, splitting and combining terms and operators in their own fields, either simple or with indexes (numerical or literal). | In Velocity there is no possibility for handling different grammars (postfix, infix) or separating binary operators in explicit CGI terms: "String placed between the two operands (in Vivisimo an operator is binary if and only if it has a middle-string specified)." In Velocity these items are not supported by the raw language itself, not even talking about tools. |
||
| Visual tools | The translators are generated by the visual Search Query Translator Generator (SQTG) tool where visually you specify what the mappings are, what functions apply over values, over already mapped sequences, you specify the grammar type, the operator grouping, etc. If there is something not supported by the generator it can be written directly in the ISR XSLT. | If you want to benefit from visual assistance you have to add all the operators and fields in a common repository so you will be mixing one content provider mappings with another just to be able to visually select sources. You cannot visually configure a mapping applicable just to one source if it is not defined globally in the operator section. "Whenever you create a form using the Standard Form template, a list of checkboxes (corresponding to the list of operators defined in the operators section) will allow you to quickly select which operators are supported. To extend this list, just go to the operators section and create new operators. See the online schema documentation for a complete specification of operators." Also the philosophy is confusing in making the fields a special case of operator so when you map fields you map operators. |
||
| Query pre-mapping | In Muse you can do query remapping at runtime. In case some fields are not supported in Muse these can be easily remapped to other supported fields (say :TITLE to :SUBJECT) via the Pre-mapping functionality. | In Velocity you either send or don’t send the query to a source that is not supported (strict or optional) but you cannot do further pre-mappings. | ||
| Other examples | In Muse, although not visually, we can group between a thousand of bib attributes, depending on the Z39.50 native source capabilities. | Z39.50 source template in Velocity only allows for 2 terms type (author and title). | ||
| Complex mappings | The complex queries can visually be taken into account as explained above. | There is a small way out for mapping non one to one source queries in Velocity, by applying a parser over what the source form initial generate (a parse element). This is complex and quite confusing (a parser to parse a parse element). It implies the knowledge of what the interim XML language looks and forces you to write manually string processing in XSLT. Besides the fact that there is no tool for this, once you lose the expression tree you will have to reconstruct it to be sure you map it one to one. This requires lexical and structural analysis – doing these analysis in XSLT is next to impossible and error prone. Only particular cases or a limited number of terms/operators might be adjusted for. |
||
| Source Query Capabilites | Each source can expose its search capabilities at runtime | No. | ||
| Dynamic limiters | Dynamic limiters depending on the capabilities of each source are as well supported – each source will be receiving individual queries according to its capabilities if the client (interface) will send the query accordingly. | No. | ||
| Parsing/ Data Extraction | More parsers are necessary | Parsing pages is necessary both for the main extraction but also for navigation steps up to the search point, and also if it is the case for the Extended parsing. The practice showed there are thousands of instances where at least one more request (and this is not the authentication part) is necessary before the search is done. | The documentation and the standard visual configuration for Velocity is with just one parser, there is room for just another one (a login parser). Also this is the only situation allowing for a wizard, and even in this case if the parsing for the record page is just a little bit more than simple markers you need to write it by hand. | |
| Muse Connectors Generator supports as many parse instructions as necessary through visual configuration. | Visually no, but the Velocity XML language supports the chaining of multiple parsers (say for a potential navigation) but that is not done in a natural way and it requires a higher expertise programmer and eventually deep training. The language interprets a parse instruction and replaces itself with another parse instruction which normally generates a record. But in case of another request you need to generated another parse instruction in the output which will be interpreted and so on. |
|||
| We are talking here about parsing intermediate pages to get navigational elements (such as, but not limited to: sessionIDs, database IDs, URLs, cookies, many other hidden fields). There are thousands of sources that natively don’t function if you don’t go step by step and perform the steps a human does when accessing it. Not to mention the case for extended parsing. These can all be done through Muse Connectors Generator. | Below is what Velocity documentation says about just a single case, the one with sessionID: "Some sites do not rely on cookies for authentication, but specify a session ID carried on as a CGI parameter. Vivísimo Velocity can comply with this, but direct configuration of the source’s XML is required. The page specifying the session ID must be parsed, and the session ID must be saved in a variable." – and there are sources that needs about 3 or 4 such steps, gathering and using variables. Although possible in the raw XML Vivisiom language there’s no wizard/tool, and not even an API through library functions and as explained above the chaining could be very misleading. |
|||
| Authenticators | Authenticators are pluggable parts of the Source Packages and a single connector can have more authenticators depending on the partner and environment. For example, many web sites allow users to login via two or more different entrances to the site. For each entrance, there is a path that leads to the site; the paths converge at some point. The authenticators enter the web site and navigate to a common point for each source. | Logon (that is the Velocity term) is bound to the source. No possibility to interchange or use multiple modules. Just a syntactic help for the input side of the HTTP protocol but no semantics – while in Muse there is a lot of semantic and parsing of the output response in the authenticator library. Also there may be more HTTP requests needed for authentication not just a single one – Muse supports this. |
||
| In Muse the programmer can select from a myriad of existent authenticators or the programmer can write a new one using the documented API library and following the procedures. | ||||
| Hence a source can have more authenticators, and the same authenticator may be used for different sources, so there exist a pluggable mechanism in Muse to offer this – in Velocity there is a strong relation between the source and its logon (note that authentication could mean more than just a "logon" – that is why Muse is using the term "authentication"). | ||||
| Effective parsing and wiring | Dynamics | In Muse Parsing starts while the page is coming (even for XML Sources as we are using SAX parsers combined with DOM just for record), not after it ended. | In Velocity the page needs to arrive entirely. | |
| Types | The Muse Connectors API and Muse Connector Builder has tens of processing possibilities for extractions – regexp is just one amongst dozens. To name just a few there are rule based extractors, rejection rules, approval rules, string token based rules, index rules, estimate parsing, table header parsing, HTTP Header parsing, date formatters, citation extractors, etc. | In Velocity there are just two types of parsers: one based on XSLT and one based on Regular Expression. These with very small variations as below: "html-xsl: Same as xsl except that it is preceded by an HTML to XML conversion. Since HTML is ambiguous, the HTML to XML conversion can be done in many ways. Vivisimo will try to close unclosed tags, add missing tags (like html and body), escape entities, and perform other normalizing steps." Hence the html-xml conversion may not be reliable because the conversion from HTML to XML at some point needs to be done heuristically based on best guesses. In Vivisimo Velocity 7.5-6 there are discussions about introducing the Java parsing in Velocity for compensating the capabilities of the existence of the two parsers and allow for more flexibility. "java: Instantiates and runs a Java class on the input data. This parser type is not finished and should not be used." |
||
| Wizard, Tools? | Muse Connector Generator could show you dozens of possibilities at each step: CONDITION, SET, SETTER, SET_URL, REPLACE, REPLACE_FIRST, REPLACE_ENTITIES, CLEAR_TAGS, REMOVE_MULTIPLE_WHITE_SPACES, REMOVE_EOL, REMOVE_HTML_COMMENTS, REMOVE_HTML_SECTIONS, REPLACE_IN_QUERY, GET_VALUE_FROM_QUERY, ADD_COOKIE, REMOVE_COOKIES, TOKENIZE, TOKENIZE_FROM_MULTIPLE_SOURCES, IF, ADD_TO_VECTOR, ADD_TO_httpProperties, GET_FROM_httpProperties, CLEAR, JAVA, CALL, RETURN, SOURCE, RULES, SPAN_RULES, MAPPINGS, SKIP_HEADERS, TABLE_HEADERS_PARSING. Muse Connector Generator also offers autocompletion for thousands of fields in the Data section for the default model or any other data model as we have many other Data Model types and all are supported by the Muse Connector Generator. | Velocity only has a list of XPaths for each field to be configured for XML extraction or regexp delimiters and few other – in total about 18 settings for each parser (and this considering all the record fields – author, date, title) – that is all the wizard for extraction configuration. Just about 10 fields can be visually configured and this just for very simple extraction cases. |
||
| Positional extraction | Based on a certain index position for text records (e.g. author is on postion 0 to 20, title 22 to 40) – Yes, through Index Rule. | No. | ||
| States | Muse Connectors Generator has dozens of state types. | Velocity has just one type of state (In case of regexp) | ||
| Direction of parsing | The parsing rules can function in both directions, both forward and backward, in order to extract a certain entity. There can be more rules that go back and forth multiple times to filter down the extraction not just two rules for the heads. There are also more configuration items to the matching rules not just the rule itself: case aware, what to find (the start, the end), action to take with the cursor, index positions, etc. Going back and forth in the string is necessary for being sure we get the most invariable markers so that the connector is reliable and tolerant to changes. | The regexp matching in Velocity together with its state can only move forward in the string, and this could make extraction harder or even impossible for cases where the entity to be extracted is only identified by an element in the middle or in the end of the entity. Such a case is when for a record or field we need to identify, for example, a checkbox in the middle of it, and then go to the first |
||
| Citation Parsing | For citation parsing extractors we have a visual generator, an automatically builder for citation extractor assisted by the programmer in just acknowledging the correctness of the extraction. It smartly matches dozens of pre-existent patterns to extract the subfields for citation: CITATION-JOURNAL, CITATION-VOLUME-ISSUE, CITATION-JOURNAL-TITLE-ABBREVIATED, CITATION-VOLUME-URL (are just a tiny part of the whole citation lot of fields). The tool applies the extractor patterns and provides results for all. The programmer just acknowledges the best results and can use many varied inputs to make sure of the correctness and reliability of the extraction. The Citation Parsing Builder also assist in grouping the rules, so that the string is decomposed top down and the best matching extractors (when we know for sure there is a date or a journal issue) are applied initially, the remaining string is thus refined and the most difficult extraction takes place in the end so that it does not have false positive elements. | Velocity does not have this notion. It is not possible to obtain citation through just regular start and end regular expression for an entity, even if it would be to write them from scratch. Also obtaining these through an XSLT parser (in case it is an XML connector) written by hand from scratch is very hard, very time consuming and could only be particular to a certain source. There is also no tool for this. |
||
| Polymorphic output | As stated above Muse Connectors are using logic to get the best out of sources when there is a polymorphic output – output changes either expected or unexpected showing more formats. For example, there is support for parsing content from result pages with different structure. The connector can be written to analyze the structure of the current page and to activate a dedicated parser for such page. A particular case is the single record parsing, but there are also other cases – there is support in Muse Connectors Generator. | No or extremly hard to achive, just with XSLT. Even if Java parser become available meanwhile it is less probable some Java API will also be available – not to mention tools. | ||
| Non-linear parsing | Support for parsing record data from different sections of the page even for the case when the records are not identified using a clear block of text in the page (not following the HTML raw text flow). For example the site may return the results in a table: the first line contains the images for the first 3 records, the second line the descriptions for the first 3 records and the third line other information for the first 3 records. In such case the data for a single record must be parsed from 3 blocks of text (the first TD element from each TR element of the table), the data for the second record is parsed from other 3 blocks of texts (the second TD element from each TR element of the table)) and the data for the third record is parsed from other 3 blocks of texts (the third TD element from each TR element of the table)). | No in regexp as backword direction is not supported. In XSLT this would be extremly difficult. |
||
| Category parsing | Support for category parsing. Based on the section of the page the results are parsed using different code. Then there might be present a "more results" native link for each category of results in part. The parsing for each "more results" from a certain category will be done using the parser for that category. | No. | ||
| Other Protocols | Parsing JSON stream and any other protocol for which Java APIs are available. | No. | ||
| XML Queries | Working with WEB Services. Sending complex XML queries defined easily through external files and parsing complex XML responses from any number of XML streams and integrating the results in a Muse record. | In Velocity you need to apply a query parser over the initial form generated parser to cater for these and you have to do this without any developer API just in the raw language. Also not everything can be obtained with this parser as it was described in the Query section. | ||
| XML Extraction | Powerful XML API that can be used to parse the XML content as it comes without waiting to receive the entire page. While parsing content from the current stream it can open other xml streams and complete the current record parsed with data parsed from the other xml streams. | No. | ||
| Complexity | Per short, any possible parsing on any number of levels which has a logic can be done with Muse because it finally uses java code and any complex parsing algorithm can be implemented in Java. But for 90% of the cases we have generators and APIs. | No, or very hard, next to impossible, to achieve; also the parsing could end up unreliable. | ||
| Debuger/Inspectors | In Muse Connector Generator we have a Step by Step debugger. Also visual inspecting of records extracted from the source through post generation tools such as SP Testing is possible. | Just log traces and requests/response logs. | ||
| Visual extractors | Besides the Citation builder we have an experimental extractor based on visual record extractor – the programmer visually selects the delimiters and the rules are automatically generated. | No. | ||
| Multilevel | In Muse the data extraction can be saved on multi-level fields. This is important in case you need to retain certain bindings/grouping between the fields. | No – only flat. | ||
| Extended Parser | We have support for Extended parsers that is extracting all the fields from the detailed record page. | Very difficult to write, no visual tool, hard to understand the resulted XML code. | ||
| Session Reusing | Straight forward support for session saving and loading parameters which for example allow for session reusing where it is the case. | In Velocity you need to do custom settings per the project and alter the main XML or other XMLs involved in the process – the task is not easy requiring very high expertise. | ||
| Proxy and URL Rewriting | Proxing (including the proxy selection via interpreting the Proxy PAC) and URL Rewriting is done transparently and nothing has to be coded in the connector, no matter how much requests are performed. The programmer needs to make sure that the Cookies, referrer and any other authorization elements are added into administrative fields of the record. The rest is just a matter of configuring the source package or the application to specify running or not through a proxy (or the PAC depending on the destination) and the MNM rewriting patterns. Of course if the source does not require to have the URL rewritten then the programmer will not configure any pattern in the source profile. | Only Proxy can be involved and if the project level proxy is not configured then the programmer has to code the proxy into the source code itself for each parse instruction. | ||
| Error and Progress Report | There are many error codes and possibilities to report from the connector as well as the status to update the progress, also fully internationalized and localized. | There are many error codes and possibilities to report from the connector as well as the status to update the progress, also fully internationalized and localized. | ||
| Quality Assurance | Besides the riguorus procedures, file versioning, issue tracking the team implements, the SP Testing tool can be used for dozens of search test cases also allowing for an easy comparison between the native behaviour and the Smart Connector behaviour. This is ensuring quality in every detail, either you search a simple query term or you search four multi word different terms with different operators. There are multiple scenario possible. Visually inspecting the extracted fields, either they are two or they are hundreds. | While Muse has a real tool for this with interactive action in Velocity there is just a test configuration screen with about 15 input boxes of a query, number of results. This is more as our Source Checker tool or test screen in Muse Source Package upgrade (which is not part of the building phase anyway). No support for record Visual inspection. Because a picture is worth a thousands words see the below images showing screens in both Muse SP Testing and Velocity Testing |
||
The Source Package Testing tool supports performing individual tests only on selected cells, where a cell identifies the search query performed and the search attribute.
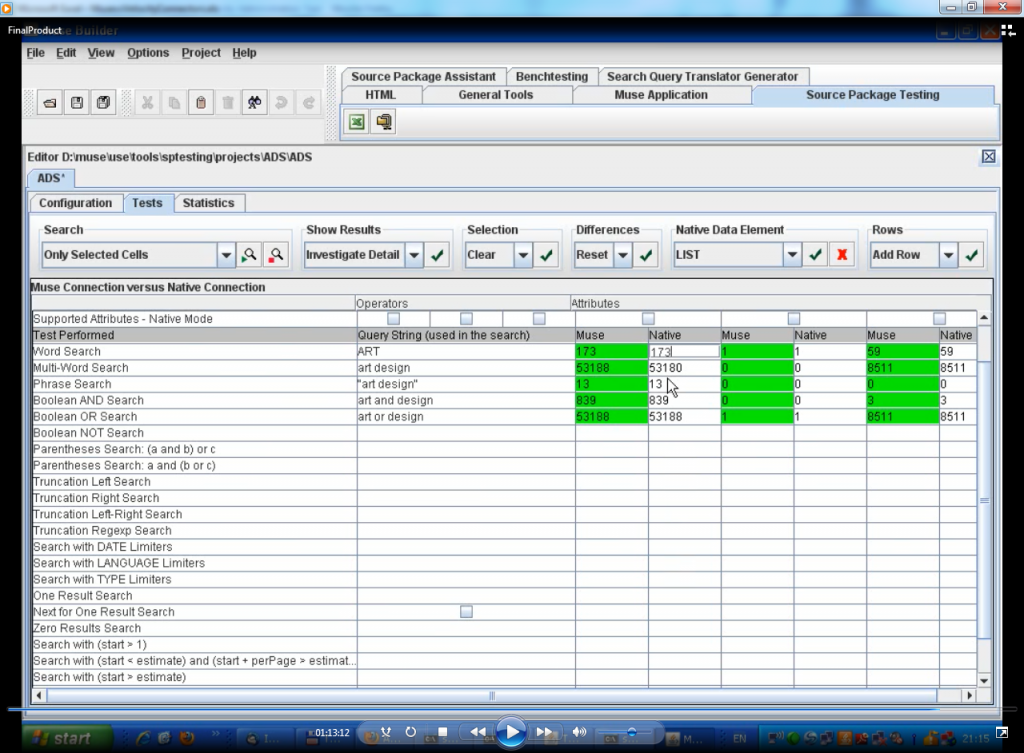
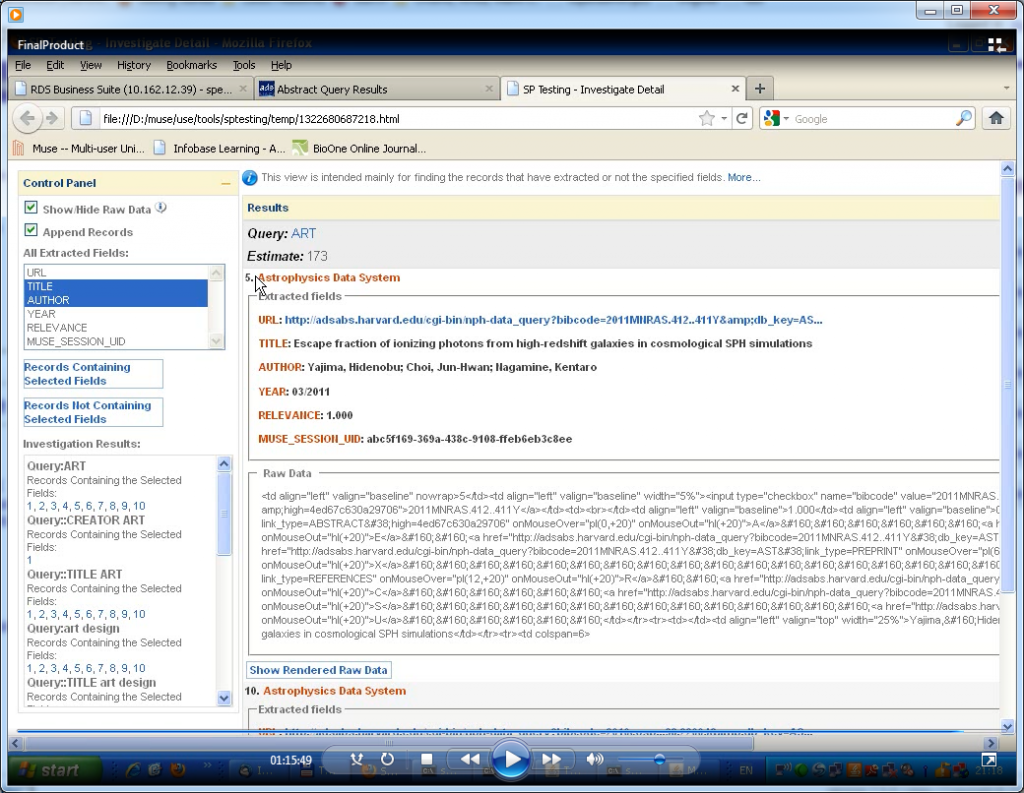
The test search results can be investigated in detail by being displayed in a browser where they can be filtered in various ways (e.g. shows the records that do/do not contain certain fields) or compared to native raw view.
In the Statistics Tab all the fields present in the records are identified and displayed and also the number of appearances for every fields can be found in a graphical representation.

Velocity Administration Tool offers just a test configuration screen with about 15 input boxes of a query, number of results. No support for record Visual inspection.
